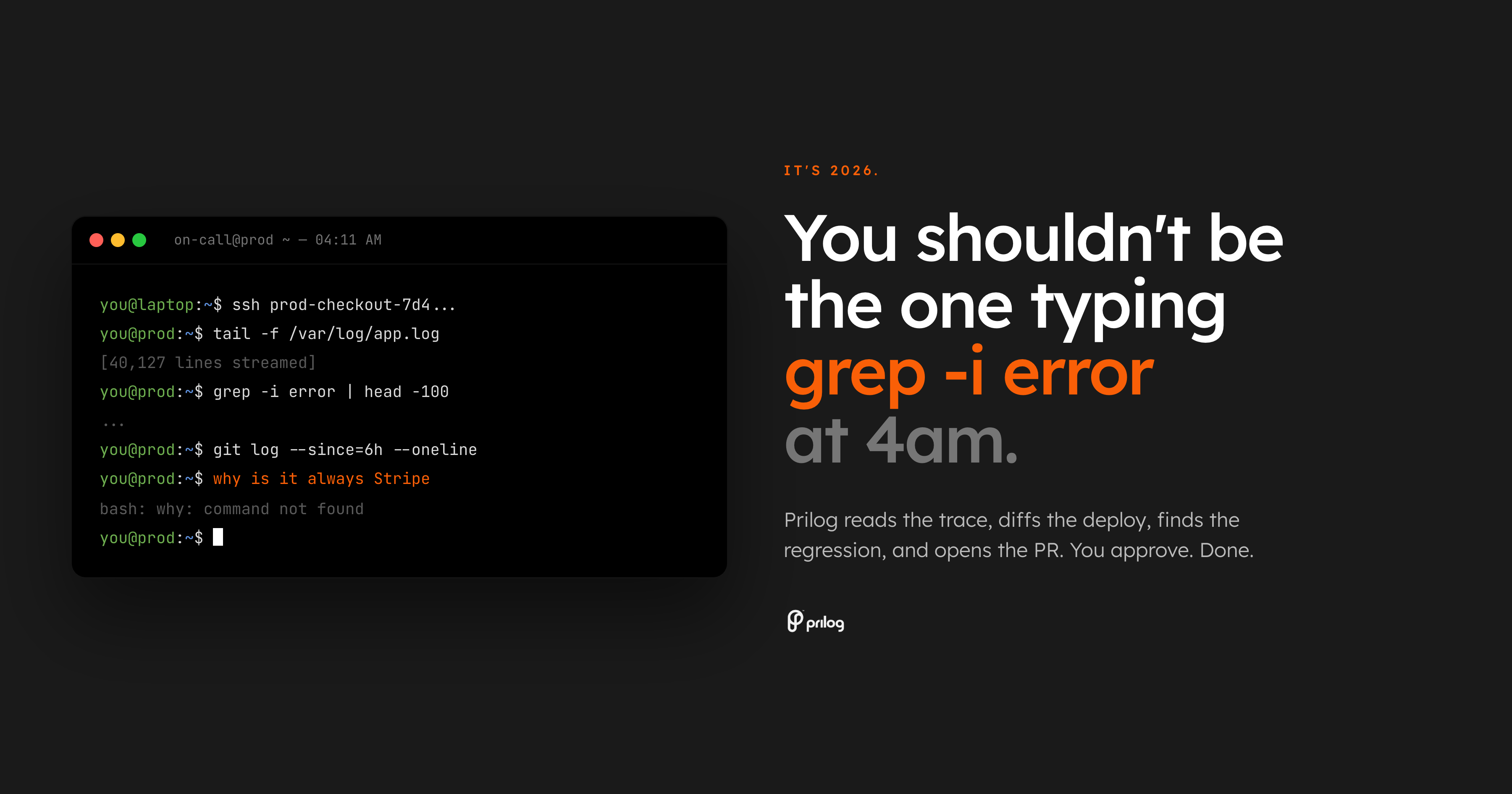
A pior parte do plantão é não ser acordado. Ele está sendo acordado e recebe um problema de pesquisa.
O alerta diz que os erros de checkout estão aumentando. O painel confirma que algo está errado. Então o verdadeiro trabalho começa: abra a visualização de rastreamento, verifique os logs, compare a última implantação, procure o proprietário, verifique o estado do sinalizador do recurso, pesquise threads antigos do Slack e decida se o bug pertence à API, pagamentos, front-end ou infraestrutura.
Isso ainda não é diagnóstico. Isso é recuperação.
O imposto oculto na resposta a incidentes
A maioria dos fluxos de trabalho de depuração de produção ainda assume que o humano é a camada de indexação. As ferramentas emitem sinais, mas o engenheiro precisa conectá-las.
Um alerta pode conhecer o serviço. Um rastreamento pode conhecer o intervalo com falha. Uma linha de log pode incluir a exceção. Git sabe o que mudou. CODEOWNERS sabe quem revisa o arquivo. O sistema de implantação sabe qual commit foi ativado. O rastreador de problemas sabe se a mesma falha aconteceu na semana passada.
Cada sistema é útil. O problema é a distância entre eles.
Quando um engenheiro passa os primeiros quinze minutos de um incidente alternando entre guias, a organização paga duas vezes. O bug permanece ativo, e a pessoa mais capaz de raciocinar sobre ele está dedicando muita atenção ao trabalho administrativo.
Pesquisa não é contexto
Procurando registros por erro pode encontrar ruído. A pesquisa de rastreamentos de um código de status pode encontrar sintomas. Pesquisar commits por carimbo de data/hora pode encontrar candidatos.
Nada disso é o mesmo que contexto.
Contexto significa que o resumo do incidente já responde às perguntas que um engenheiro experiente faria primeiro:
- Qual caminho do cliente está falhando?
- Qual serviço, endpoint, trabalho ou fila está envolvido?
- A falha começou após uma implantação?
- Qual caminho de código aparece no rastreamento?
- Quem possui os arquivos relevantes?
- Esta assinatura já apareceu antes?
- Qual é a menor solução plausível ou caminho de reversão?
Esse resumo deve existir antes que o engenheiro de plantão comece a digitar.
Uma primeira tela melhor
A primeira tela de um incidente deve parecer um arquivo de caso preparado, e não um terminal em branco.
Deve mostrar o sinal de produção, o caminho do código suspeito, o conjunto de alterações recentes e o proprietário. Deve separar os fatos das suposições. Deve dizer quando a evidência é fraca. Se houver confiança suficiente para redigir uma solicitação pull de correção, isso deverá ser feito com os logs e rastreamentos relevantes anexados à revisão.
Isso não substitui o julgamento de plantão. Isso o protege.
A atenção humana é melhor aproveitada perguntando: "Essa é a solução certa?" do que "Qual guia tinha a pista?"
O que a automação deve fazer antes da revisão
Uma boa automação de incidentes deve lidar com as etapas enfadonhas da investigação:
- Agrupe alertas duplicados e eventos de erro.
- Reúna os rastreamentos e logs mais úteis em um resumo.
- Compare a janela de falha com o histórico de implantação.
- Mapeie frames e extensões de pilha para arquivos, funções e proprietários.
- Elabore um patch mínimo apenas quando as evidências o apoiarem.
- Explique as suposições que um revisor precisa validar.
A saída ainda pode ser uma solicitação pull normal. Na verdade, deveria ser. As solicitações pull já trazem revisão, CI, propriedade, discussão e trilha de auditoria.
O padrão de plantão deve mudar
Estamos em 2026. A linha de base não deve ser um engenheiro compondo manualmente comandos shell às 4 da manhã enquanto a produção está interrompida.
A linha de base deve ser um sistema que leia o incidente, reúna as evidências circundantes, conecte-as ao código e entregue ao proprietário uma próxima etapa revisável.
O plantão sempre exigirá julgamento. Não deve ser necessário agir primeiro como um mecanismo de pesquisa.