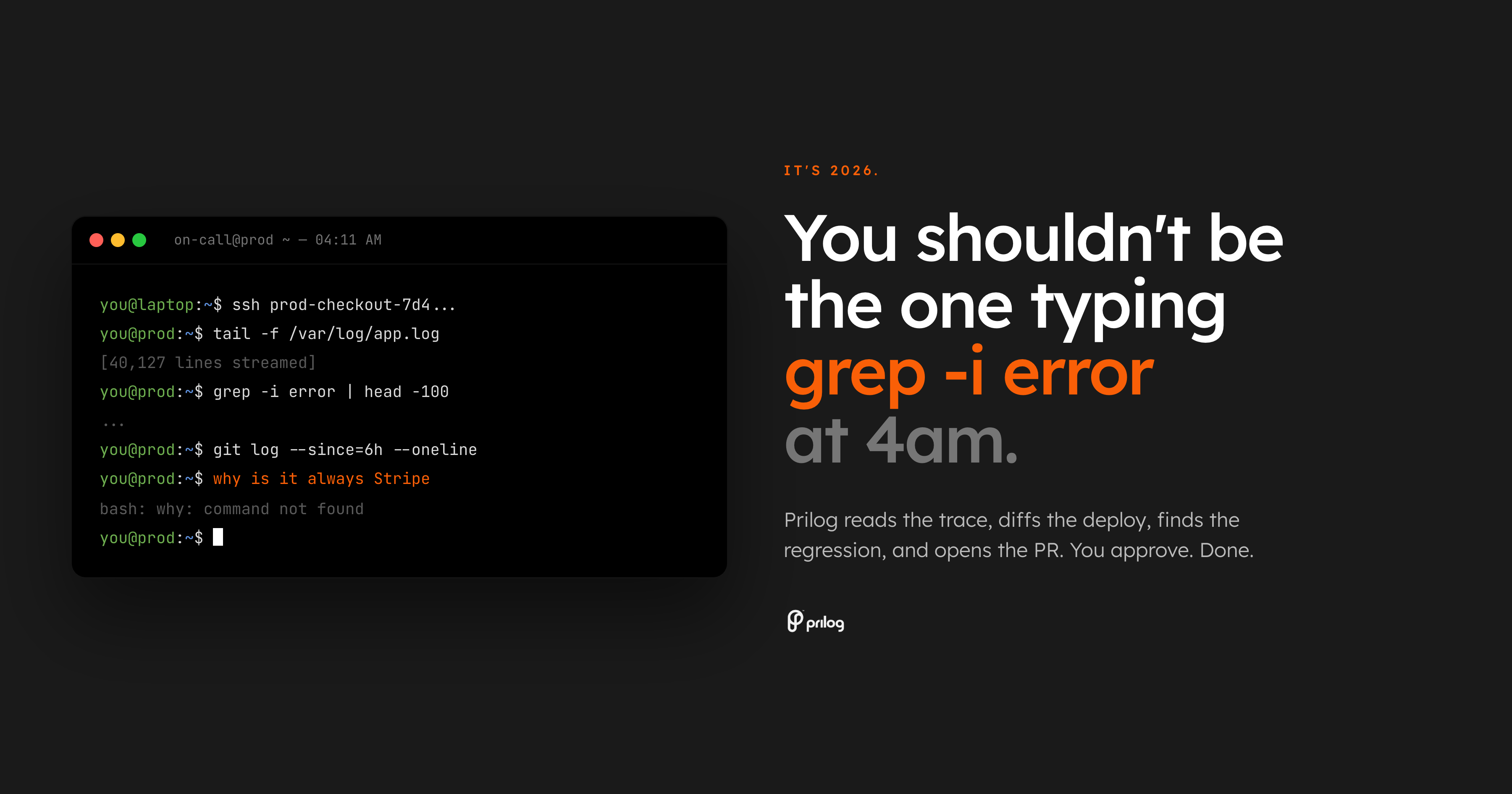
La parte peggiore del servizio di guardia è non essere svegliati. È stato svegliato e gli è stato assegnato un problema di ricerca.
L'avviso dice che gli errori di pagamento sono in aumento. La dashboard conferma che qualcosa non va. Quindi inizia il vero lavoro: aprire la visualizzazione traccia, scansionare i log, confrontare l'ultima distribuzione, cercare il proprietario, controllare lo stato del flag della funzionalità, cercare vecchi thread Slack e decidere se il bug appartiene all'API, ai pagamenti, al frontend o all'infrastruttura.
Questa non è ancora una diagnosi. Questo è il recupero.
La tassa nascosta nella risposta agli incidenti
La maggior parte dei flussi di lavoro di debug della produzione presuppone ancora che il livello di indicizzazione sia umano. Gli strumenti emettono segnali, ma l'ingegnere deve collegarli.
Un avviso potrebbe conoscere il servizio. Una traccia potrebbe conoscere l'intervallo non riuscito. Una riga di registro potrebbe includere l'eccezione. Git sa cosa è cambiato. CODEOWNERS sa chi esamina il file. Il sistema di distribuzione sa quale commit è stato attivato. Il tracker dei problemi sa se si è verificato lo stesso errore la settimana scorsa.
Ogni sistema è utile. Il problema è il divario tra loro.
Quando un tecnico trascorre i primi quindici minuti di un incidente spostandosi tra le schede, l'organizzazione paga due volte. Il bug rimane vivo e la persona più in grado di ragionare su di esso sta attirando l'attenzione sul lavoro d'ufficio.
La ricerca non è contesto
Ricerca di log per errore può trovare rumore. La ricerca di tracce per un codice di stato può trovare sintomi. La ricerca dei commit tramite timestamp può trovare candidati.
Niente di tutto ciò è uguale al contesto.
Il contesto significa che la descrizione dell'incidente risponde già alle domande che un ingegnere esperto porrebbe per prime:
- Quale percorso del cliente sta fallendo?
- Quale servizio, endpoint, lavoro o coda è coinvolto?
- L'errore è iniziato dopo una distribuzione?
- Quale percorso del codice appare nella traccia?
- Chi possiede i file rilevanti?
- Questa firma è già apparsa?
- Qual è il percorso di correzione o ripristino plausibile più piccolo?
Tale brief dovrebbe esistere prima che il tecnico di guardia inizi a digitare.
Una prima schermata migliore
La prima schermata di un incidente dovrebbe sembrare un file del caso preparato, non un terminale vuoto.
Dovrebbe mostrare il segnale di produzione, il percorso del codice sospetto, il set di modifiche recenti e il proprietario. Dovrebbe separare i fatti dalle ipotesi. Dovrebbe dire quando le prove sono deboli. Se c'è abbastanza fiducia per redigere una richiesta pull di riparazione, dovrebbe farlo con i log e le tracce pertinenti allegati alla revisione.
Ciò non sostituisce il giudizio di guardia. Lo protegge.
È meglio spendere l'attenzione umana chiedendosi: "È questa la soluzione giusta?" piuttosto che "Quale scheda aveva l'indizio?"
Cosa dovrebbe fare l'automazione prima della revisione
Una buona automazione degli incidenti dovrebbe gestire le noiose fasi dell’indagine:
- Raggruppare avvisi duplicati ed eventi di errore.
- Raccogli le tracce e i registri più utili in un unico riepilogo.
- Confronta la finestra di errore con la cronologia di distribuzione.
- Mappare stack frame e intervalli su file, funzioni e proprietari.
- Redigere una patch minima solo quando le prove lo supportano.
- Spiegare le ipotesi che un revisore deve convalidare.
L'output può comunque essere una normale richiesta pull. In effetti, dovrebbe essere. Le richieste pull comportano già revisione, CI, proprietà, discussione e una traccia di controllo.
Lo standard di guardia dovrebbe cambiare
È il 2026. La linea di base non dovrebbe essere un ingegnere che compone manualmente i comandi della shell alle 4 del mattino mentre la produzione è interrotta.
La base di riferimento dovrebbe essere un sistema che legga l'incidente, raccolga le prove circostanti, le colleghi al codice e fornisca al proprietario un passaggio successivo rivedibile.
Il servizio di guardia richiederà sempre un giudizio. Non dovrebbe richiedere di agire prima come un motore di ricerca.