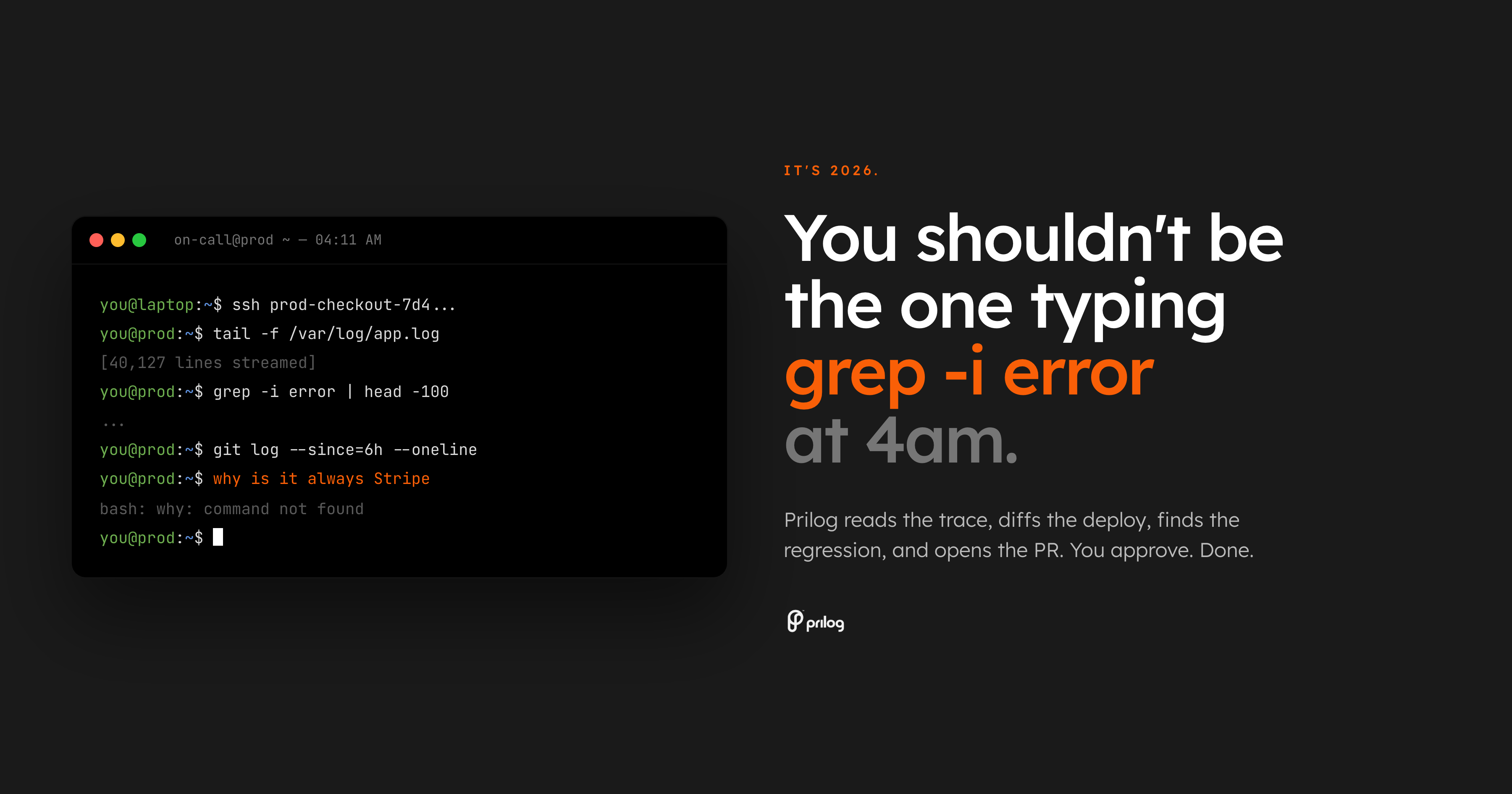
Le pire dans la garde, c'est de ne pas être réveillé. Il est réveillé et confronté à un problème de recherche.
L'alerte indique que les erreurs de paiement sont en augmentation. Le tableau de bord confirme que quelque chose ne va pas. Ensuite, le vrai travail commence: ouvrez la vue de trace, analysez les journaux, comparez le dernier déploiement, recherchez le propriétaire, vérifiez l'état de l'indicateur de fonctionnalité, recherchez les anciens threads Slack et décidez si le bogue appartient à l'API, aux paiements, au frontend ou à l'infrastructure.
Ce n'est pas encore un diagnostic. C'est la récupération.
La taxe cachée dans la réponse aux incidents
La plupart des workflows de débogage de production supposent toujours que l’humain est la couche d’indexation. Les outils émettent des signaux, mais l'ingénieur doit les connecter.
Une alerte pourrait connaître le service. Une trace pourrait connaître la durée défaillante. Une ligne de journal peut inclure l'exception. Git sait ce qui a changé. CODEOWNERS sait qui examine le fichier. Le système de déploiement sait quel commit a été mis en ligne. Le système de suivi des problèmes sait si le même échec s'est produit la semaine dernière.
Chaque système est utile. Le problème, c'est l'écart qui les sépare.
Lorsqu'un ingénieur passe les quinze premières minutes d'un incident à parcourir les onglets, l'organisation paie deux fois. Le bug reste actif, et la personne la mieux à même d’en raisonner se concentre sur le travail de bureau.
La recherche n'est pas contextuelle
Recherche de journaux pour erreur peut trouver du bruit. La recherche de traces pour un code d'état peut détecter des symptômes. La recherche de commits par horodatage permet de trouver des candidats.
None of that is the same as context.
Le contexte signifie que le résumé de l'incident répond déjà aux questions qu'un ingénieur expérimenté se poserait en premier:
- Quel parcours client échoue?
- Quel service, point de terminaison, tâche ou file d'attente est impliqué?
- L'échec a-t-il commencé après un déploiement?
- Quel chemin de code apparaît dans la trace?
- À qui appartiennent les fichiers concernés?
- Cette signature est-elle déjà apparue?
- Quelle est la plus petite solution plausible ou chemin de restauration?
Ce brief doit exister avant que l'ingénieur de garde ne commence à taper.
Un meilleur premier écran
Le premier écran d’un incident doit ressembler à un dossier préparé et non à un terminal vierge.
Il doit afficher le signal de production, le chemin de code suspecté, l'ensemble de modifications récentes et le propriétaire. Il convient de séparer les faits des suppositions. Il faudrait le dire lorsque les preuves sont faibles. S'il y a suffisamment de confiance pour rédiger une demande d'extraction de correction, il doit le faire avec les journaux et traces pertinents joints à l'examen.
Cela ne remplace pas le jugement de garde. Cela le protège.
Il vaut mieux consacrer l’attention humaine à se demander: « Est-ce la bonne solution? » que: "Quel onglet avait l'indice?"
Ce que l'automatisation devrait faire avant l'examen
Une bonne automatisation des incidents doit gérer les étapes d'enquête ennuyeuses:
- Regroupez les alertes et les événements d’erreur en double.
- Réunissez les traces et les journaux les plus utiles dans un seul résumé.
- Comparez la fenêtre d'échec avec l'historique de déploiement.
- Mappez les cadres et les étendues de la pile aux fichiers, fonctions et propriétaires.
- Rédigez un correctif minimal uniquement lorsque les preuves le soutiennent.
- Expliquez les hypothèses qu'un évaluateur doit valider.
La sortie peut toujours être une demande d’extraction normale. En fait, cela devrait l’être. Les demandes d'extraction comportent déjà une révision, une CI, une propriété, une discussion et une piste d'audit.
La norme de garde devrait changer
Nous sommes en 2026. La référence ne devrait pas être un ingénieur composant manuellement des commandes shell à 4 heures du matin alors que la production est interrompue.
La référence doit être un système qui lit l'incident, rassemble les preuves environnantes, les connecte au code et propose au propriétaire une prochaine étape révisable.
On-call will always require judgment. Cela ne devrait pas nécessiter d’abord d’agir comme un moteur de recherche.