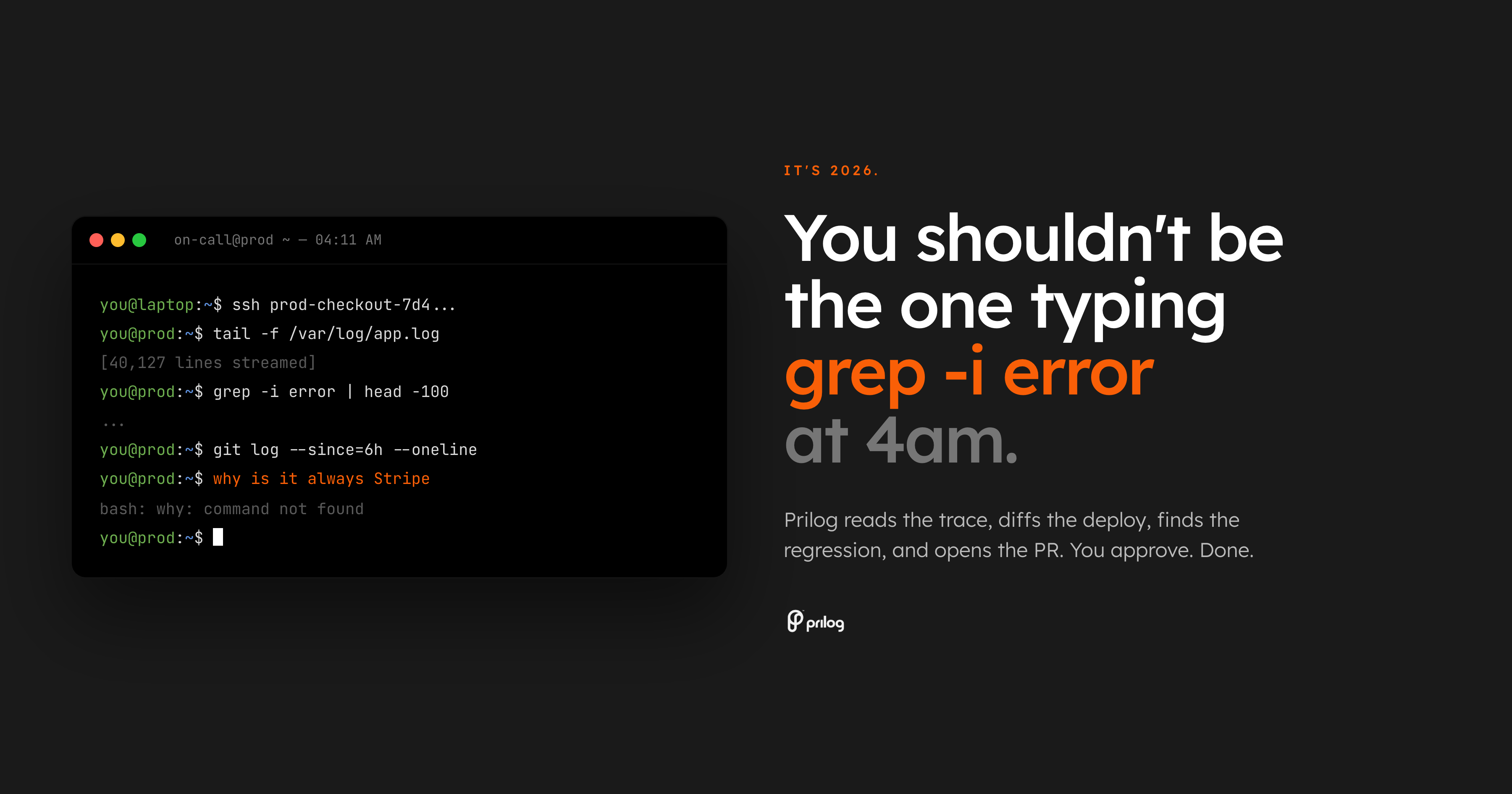
Das Schlimmste am Bereitschaftsdienst ist, nicht geweckt zu werden. Es wird aufgeweckt und ein Suchproblem übergeben.
Die Warnung besagt, dass die Fehler beim Bezahlen zunehmen. Das Dashboard bestätigt, dass etwas nicht stimmt. Dann beginnt die eigentliche Arbeit: Öffnen Sie die Trace-Ansicht, scannen Sie Protokolle, vergleichen Sie die letzte Bereitstellung, suchen Sie nach dem Eigentümer, überprüfen Sie den Feature-Flag-Status, durchsuchen Sie alte Slack-Threads und entscheiden Sie, ob der Fehler zur API, zu Zahlungen, zum Frontend oder zur Infrastruktur gehört.
Das ist noch keine Diagnose. Das ist Retrieval.
Die versteckte Steuer bei der Reaktion auf Vorfälle
Bei den meisten Produktions-Debugging-Workflows wird immer noch davon ausgegangen, dass der Mensch die Indizierungsebene übernimmt. Werkzeuge senden Signale aus, aber der Ingenieur muss sie verbinden.
Eine Warnung könnte den Dienst kennen. Ein Trace kennt möglicherweise die fehlerhafte Spanne. Eine Protokollzeile könnte die Ausnahme enthalten. Git weiß, was sich geändert hat. CODEOWNERS weiß, wer die Datei überprüft. Das Bereitstellungssystem weiß, welcher Commit live gegangen ist. Der Issue-Tracker weiß, ob derselbe Fehler letzte Woche aufgetreten ist.
Jedes System ist nützlich. Das Problem ist die Kluft zwischen ihnen.
Wenn ein Ingenieur die ersten fünfzehn Minuten eines Vorfalls damit verbringt, zwischen den Registerkarten zu wechseln, zahlt das Unternehmen doppelt. Der Fehler bleibt bestehen, und die Person, die am besten darüber nachdenken kann, konzentriert sich auf die Büroarbeit.
Suche ist kein Kontext
Durchsuchen von Protokollen nach Fehler kann Lärm finden. Durch die Spurensuche nach einem Statuscode können Symptome gefunden werden. Durch die Suche nach Commits nach Zeitstempel können Kandidaten gefunden werden.
Nichts davon ist dasselbe wie Kontext.
Kontext bedeutet, dass die Vorfallbeschreibung bereits die Fragen beantwortet, die ein erfahrener Ingenieur zuerst stellen würde:
- Welcher Kundenpfad schlägt fehl?
- Um welchen Dienst, Endpunkt, Job oder welche Warteschlange handelt es sich?
- Hat der Fehler nach einer Bereitstellung begonnen?
- Welcher Codepfad erscheint im Trace?
- Wem gehören die entsprechenden Dateien?
- Ist diese Signatur schon einmal aufgetaucht?
- Was ist der kleinste plausible Fix- oder Rollback-Pfad?
Dieser Auftrag sollte vorliegen, bevor der Bereitschaftstechniker mit der Eingabe beginnt.
Ein besserer erster Bildschirm
Der erste Bildschirm bei einem Vorfall sollte sich wie eine vorbereitete Fallakte anfühlen und nicht wie ein leeres Terminal.
Es sollte das Produktionssignal, den vermuteten Codepfad, den letzten Änderungssatz und den Eigentümer anzeigen. Es sollte Fakten von Vermutungen trennen. Es sollte angegeben werden, wenn die Beweise schwach sind. Wenn genügend Vertrauen vorhanden ist, um eine Pull-Anfrage zur Behebung zu verfassen, sollte dies mit den relevanten Protokollen und Traces erfolgen, die der Überprüfung beigefügt sind.
Dies ersetzt nicht die Beurteilung auf Abruf. Es schützt es.
Die menschliche Aufmerksamkeit sollte besser darauf verwendet werden, sich zu fragen: „Ist das die richtige Lösung?“ als: „Welche Registerkarte hatte den Hinweis?“
Was die Automatisierung vor der Überprüfung tun sollte
Eine gute Automatisierung von Vorfällen sollte die langweiligen Untersuchungsschritte bewältigen:
- Clustern Sie doppelte Warnungen und Fehlerereignisse.
- Fassen Sie die nützlichsten Traces und Protokolle in einer Zusammenfassung zusammen.
- Vergleichen Sie das Fehlerfenster mit dem Bereitstellungsverlauf.
- Ordnen Sie Stapelrahmen und -spannen Dateien, Funktionen und Besitzern zu.
- Entwerfen Sie nur dann einen minimalen Patch, wenn die Beweise dies unterstützen.
- Erläutern Sie die Annahmen, die ein Prüfer validieren muss.
Die Ausgabe kann weiterhin eine normale Pull-Anfrage sein. Eigentlich sollte es so sein. Pull-Anfragen enthalten bereits Überprüfung, CI, Eigentümerschaft, Diskussion und einen Prüfpfad.
Der Rufbereitschaftsstandard soll sich ändern
Wir schreiben das Jahr 2026. Die Grundlinie sollte nicht darin bestehen, dass ein Ingenieur um 4 Uhr morgens manuell Shell-Befehle verfasst, während die Produktion unterbrochen ist.
Die Basis sollte ein System sein, das den Vorfall liest, die umgebenden Beweise sammelt, sie mit Code verknüpft und dem Eigentümer einen überprüfbaren nächsten Schritt gibt.
Bereitschaftsdienst erfordert immer Urteilsvermögen. Es sollte nicht erforderlich sein, sich zunächst wie eine Suchmaschine zu verhalten.