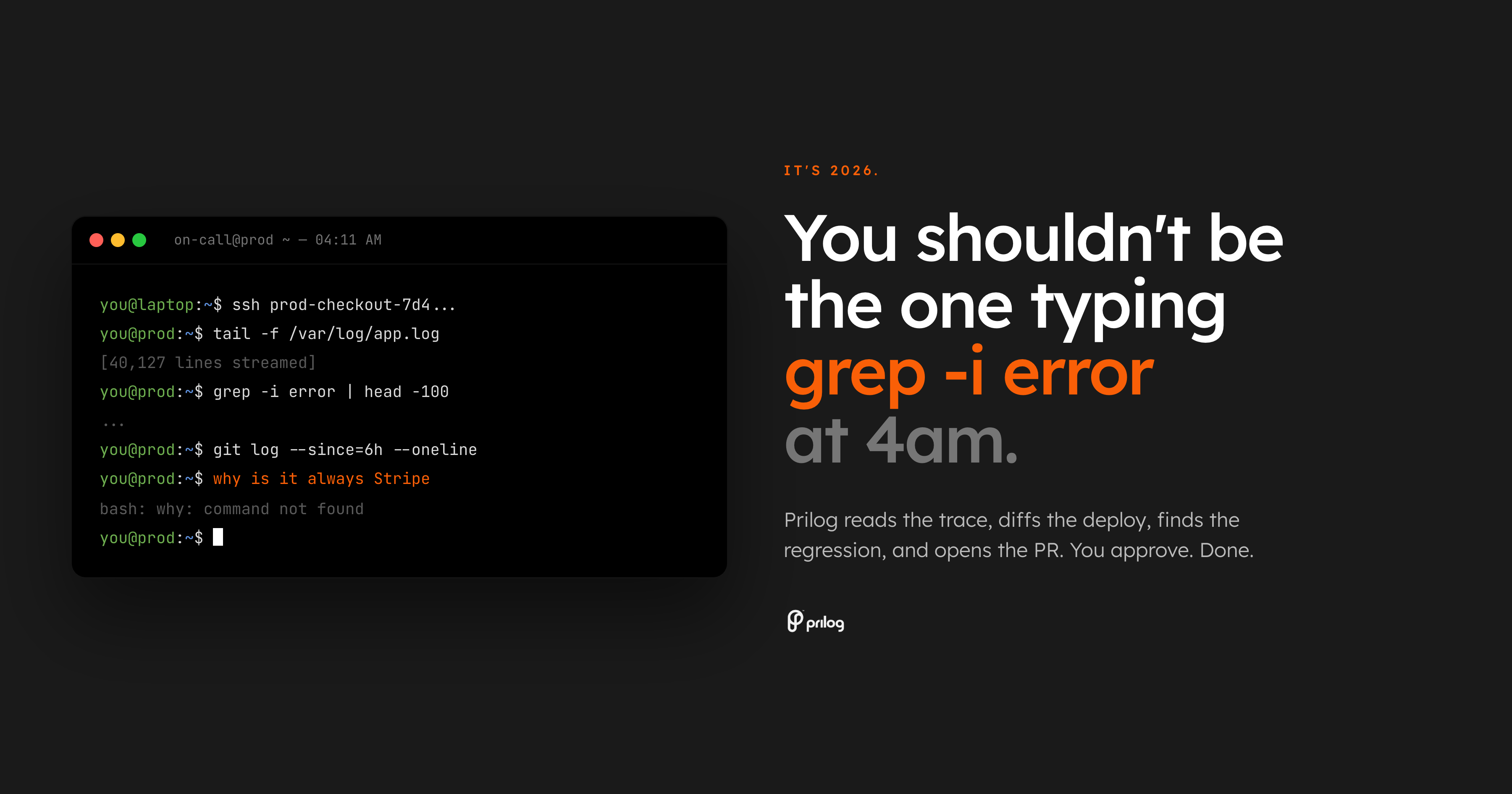
Het ergste van oproepkracht is dat je niet wakker wordt gemaakt. Het wordt gewekt en krijgt een zoekprobleem.
De waarschuwing zegt dat het aantal betaalfouten toeneemt. Het dashboard bevestigt dat er iets mis is. Dan begint het echte werk: open de traceringsweergave, scan logs, vergelijk de laatste implementatie, zoek naar de eigenaar, controleer de vlagstatus van de functie, doorzoek oude Slack-threads en beslis of de bug tot API, betalingen, frontend of infrastructuur behoort.
Dat is nog geen diagnose. Dat is ophalen.
De verborgen belasting bij incidentrespons
De meeste productie-foutopsporingsworkflows gaan er nog steeds van uit dat de mens de indexeringslaag is. Gereedschappen zenden signalen uit, maar de ingenieur moet ze verbinden.
Een waarschuwing kan de service kennen. Een trace kan de falende spanwijdte kennen. Een logregel kan de uitzondering bevatten. Git weet wat er is veranderd. CODEOWNERS weten wie het bestand beoordeelt. Het implementatiesysteem weet welke commit live is gegaan. De issuetracker weet of vorige week dezelfde fout heeft plaatsgevonden.
Elk systeem is nuttig. Het probleem is de kloof daartussen.
Wanneer een ingenieur de eerste vijftien minuten van een incident tussen tabbladen doorbrengt, betaalt de organisatie twee keer. De bug blijft bestaan, en de persoon die er het beste over kan redeneren, richt de aandacht op administratief werk.
Zoeken is geen context
Logboeken zoeken naar fout lawaai kan vinden. Door sporen te zoeken naar een statuscode kunnen symptomen worden gevonden. Door commits te zoeken op tijdstempel kun je kandidaten vinden.
Niets daarvan is hetzelfde als context.
Context betekent dat de incidentbrief al de vragen beantwoordt die een ervaren ingenieur als eerste zou stellen:
- Welk klantpad faalt?
- Om welke service, eindpunt, taak of wachtrij gaat het?
- Is de fout begonnen na een implementatie?
- Welk codepad verschijnt in de trace?
- Wie is eigenaar van de betreffende bestanden?
- Is deze handtekening eerder verschenen?
- Wat is het kleinste plausibele herstel- of terugdraaipad?
Die opdracht moet bestaan voordat de dienstdoende ingenieur begint te typen.
Een beter eerste scherm
Het eerste scherm bij een incident moet aanvoelen als een voorbereid dossier, niet als een lege terminal.
Het moet het productiesignaal, het vermoedelijke codepad, de recente wijzigingsset en de eigenaar tonen. Het moet feiten van gissingen scheiden. Er zou moeten staan wanneer het bewijs zwak is. Als er voldoende vertrouwen is om een herstel-pull-verzoek op te stellen, moet dit worden gedaan met de relevante logboeken en traceringen die bij de beoordeling zijn gevoegd.
Dit vervangt geen oordeel op afroep. Het beschermt het.
De menselijke aandacht kan beter worden besteed aan de vraag: "Is dit de juiste oplossing?" dan: "Welk tabblad had de aanwijzing?"
Wat automatisering moet doen vóór beoordeling
Goede incidentautomatisering moet de saaie onderzoeksstappen aankunnen:
- Cluster dubbele waarschuwingen en foutgebeurtenissen.
- Breng de nuttigste traceringen en logs samen in één samenvatting.
- Vergelijk het foutvenster met de implementatiegeschiedenis.
- Wijs stapelframes en -bereiken toe aan bestanden, functies en eigenaren.
- Stel alleen een minimale patch op als het bewijsmateriaal dit ondersteunt.
- Leg uit welke aannames een recensent moet valideren.
De uitvoer kan nog steeds een normaal pull-verzoek zijn. In feite zou het zo moeten zijn. Pull-aanvragen bevatten al beoordeling, CI, eigendom, discussie en een audittrail.
De norm voor bereikbaarheid moet veranderen
Het is 2026. De basislijn zou niet moeten zijn dat een ingenieur om vier uur 's ochtends handmatig shell-opdrachten opstelt terwijl de productie wordt onderbroken.
De basislijn moet een systeem zijn dat het incident leest, het omliggende bewijsmateriaal verzamelt, dit aan code koppelt en de eigenaar een beoordeelbare volgende stap overhandigt.
Op afroep is altijd een beoordelingsvermogen vereist. Het zou niet nodig moeten zijn om eerst als een zoekmachine te handelen.