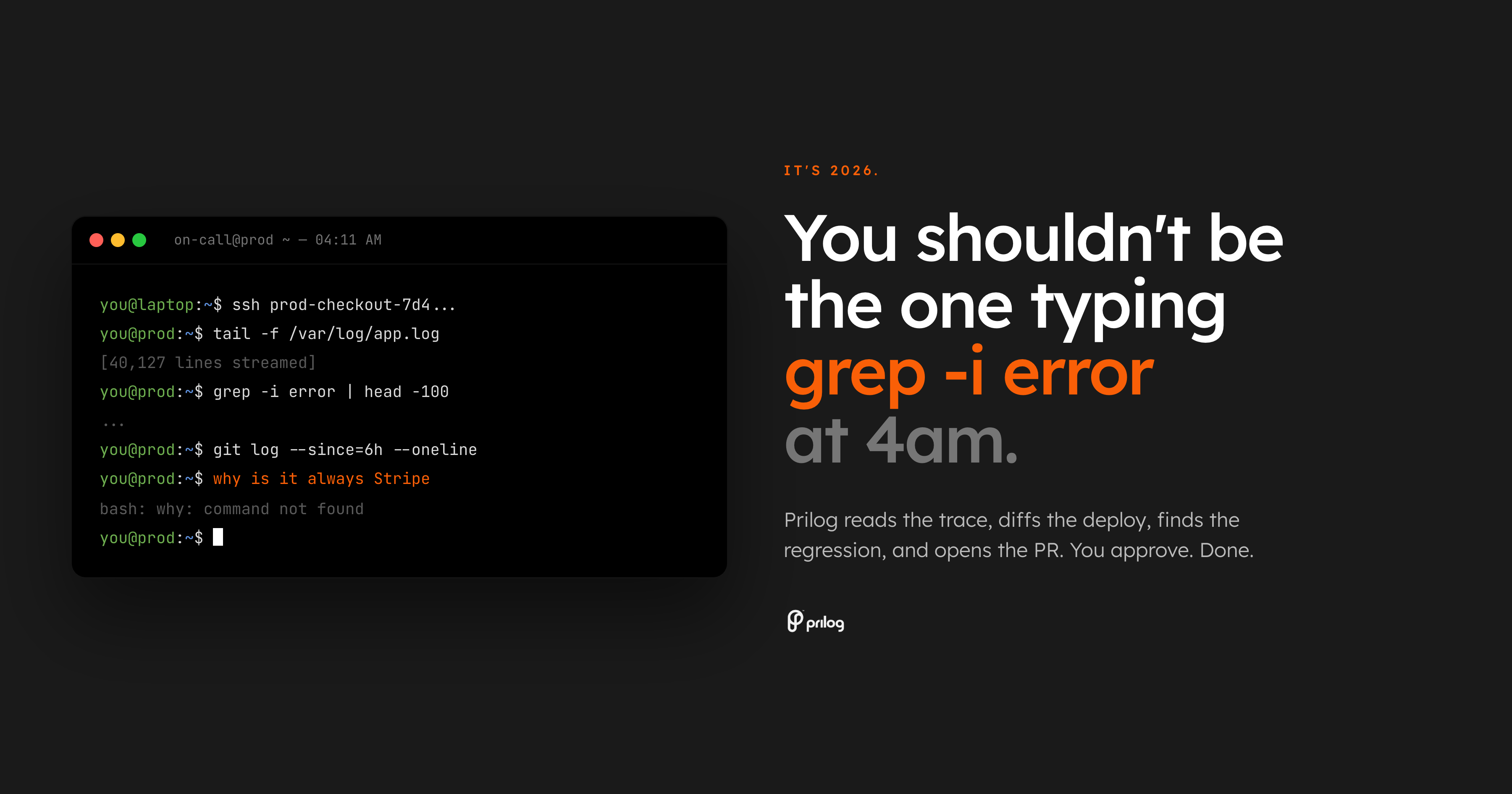
La peor parte de la guardia es que no te despierten. Se está despertando y se le está entregando un problema de búsqueda.
La alerta dice que los errores de pago están aumentando. El tablero confirma que algo anda mal. Luego comienza el verdadero trabajo: abra la vista de seguimiento, escanee los registros, compare la última implementación, busque el propietario, verifique el estado del indicador de la función, busque hilos antiguos de Slack y decida si el error pertenece a la API, los pagos, la interfaz o la infraestructura.
Eso aún no es un diagnóstico. Eso es recuperación.
El impuesto oculto en la respuesta a incidentes
La mayoría de los flujos de trabajo de depuración de producción todavía asumen que el ser humano es la capa de indexación. Las herramientas emiten señales, pero el ingeniero tiene que conectarlas.
Una alerta podría conocer el servicio. Un rastro podría conocer el tramo fallido. Una línea de registro podría incluir la excepción. Git sabe qué cambió. CODEOWNERS sabe quién revisa el archivo. El sistema de implementación sabe qué confirmación se puso en marcha. El rastreador de problemas sabe si ocurrió el mismo error la semana pasada.
Cada sistema es útil. El problema es la brecha entre ellos.
Cuando un ingeniero pasa los primeros quince minutos de un incidente moviéndose entre pestañas, la organización paga el doble. El error permanece vivo y la persona más capaz de razonar sobre él es la que concentra su atención en el trabajo administrativo.
La búsqueda no es contexto
Buscando registros para error puede encontrar ruido. La búsqueda de rastros de un código de estado puede encontrar síntomas. La búsqueda de confirmaciones por marca de tiempo puede encontrar candidatos.
Nada de eso es lo mismo que el contexto.
El contexto significa que el informe del incidente ya responde a las preguntas que un ingeniero experimentado haría primero:
- ¿Qué ruta de cliente está fallando?
- ¿Qué servicio, punto final, trabajo o cola está involucrado?
- ¿La falla comenzó después de una implementación?
- ¿Qué ruta de código aparece en el seguimiento?
- ¿A quién pertenecen los archivos relevantes?
- ¿Ha aparecido esta firma antes?
- ¿Cuál es la solución o ruta de reversión más pequeña posible?
Ese informe debe existir antes de que el ingeniero de guardia comience a escribir.
Una mejor primera pantalla
La primera pantalla de un incidente debería parecer un expediente de caso preparado, no una terminal en blanco.
Debería mostrar la señal de producción, la ruta del código sospechoso, el conjunto de cambios recientes y el propietario. Debería separar los hechos de las conjeturas. Debería decir cuándo la evidencia es débil. Si hay suficiente confianza para redactar una solicitud de extracción de corrección, debe hacerlo con los registros y rastreos relevantes adjuntos a la revisión.
Esto no reemplaza el juicio de guardia. Lo protege.
Es mejor emplear la atención humana preguntando: "¿Es esta la solución correcta?" que "¿Qué pestaña tenía la pista?"
Qué debe hacer la automatización antes de la revisión
Una buena automatización de incidentes debería encargarse de los aburridos pasos de la investigación:
- Agrupe alertas duplicadas y eventos de error.
- Reúna los seguimientos y registros más útiles en un solo resumen.
- Compare la ventana de error con el historial de implementación.
- Asigne marcos y tramos de pila a archivos, funciones y propietarios.
- Redacte un parche mínimo sólo cuando la evidencia lo respalde.
- Explique los supuestos que un revisor debe validar.
El resultado aún puede ser una solicitud de extracción normal. De hecho, debería serlo. Las solicitudes de extracción ya incluyen revisión, CI, propiedad, discusión y un seguimiento de auditoría.
El estándar de guardia debería cambiar
Estamos en 2026. La línea de base no debería ser un ingeniero que componga manualmente comandos de shell a las 4 a. m. mientras la producción está interrumpida.
La línea de base debe ser un sistema que lea el incidente, recopile la evidencia circundante, la conecte al código y le proporcione al propietario un siguiente paso revisable.
La guardia siempre requerirá criterio. No debería requerir actuar primero como un motor de búsqueda.