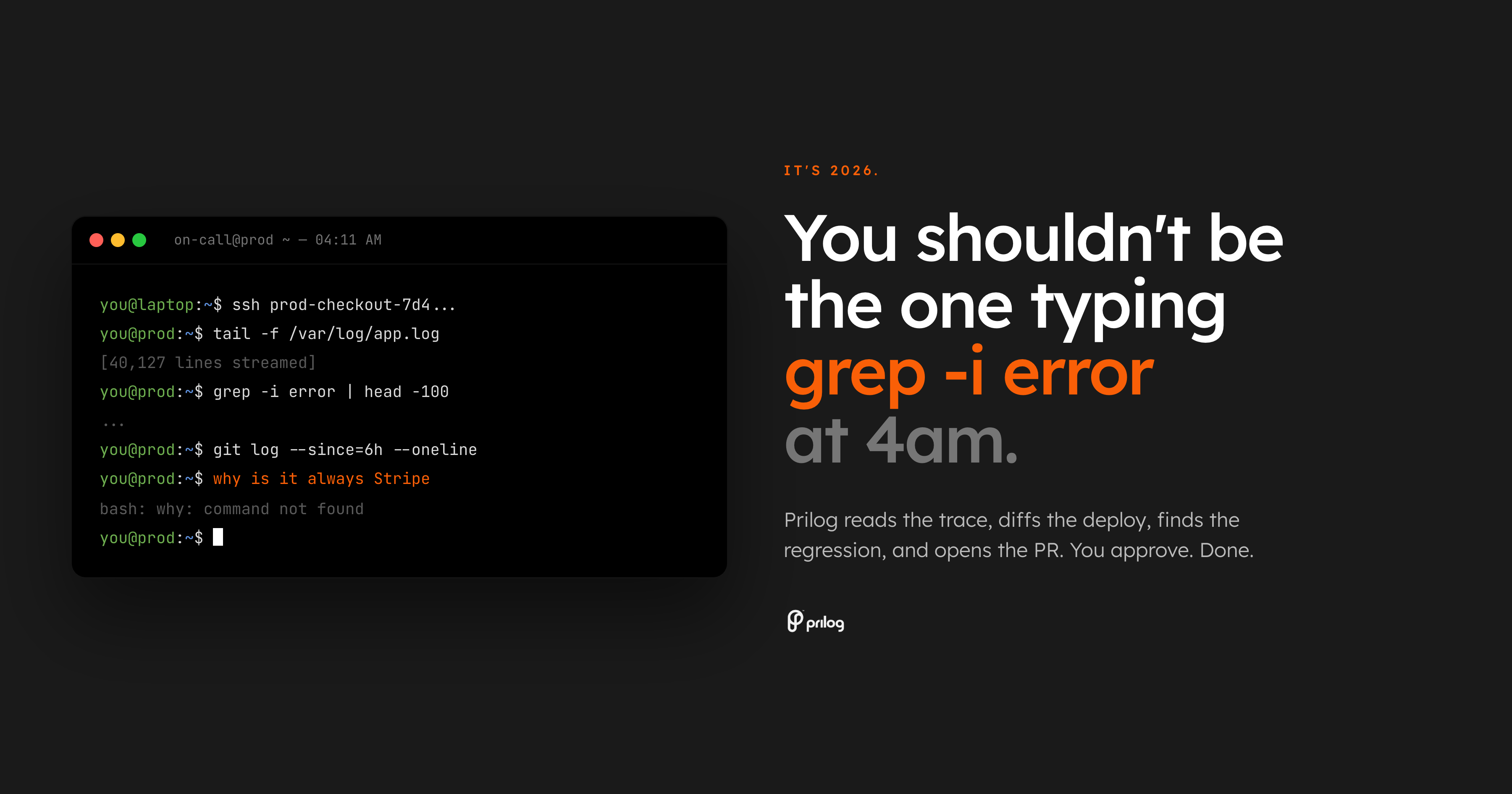
值班最糟糕的部分是不被叫醒。它正在被唤醒并交给一个搜索问题。
警报称结账错误正在增加。仪表板确认出现问题。然后真正的工作开始:打开跟踪视图,扫描日志,比较上次部署,查找所有者,检查功能标志状态,搜索旧的 Slack 线程,并确定错误是否属于 API、支付、前端或基础设施。
那还不是诊断。那就是检索。
事件响应中的隐性税收
大多数生产调试工作流程仍然假设人类是索引层。工具发出信号,但工程师必须连接它们。
警报可能知道该服务。跟踪可能知道失败的跨度。日志行可能包含异常。 Git 知道发生了什么变化。代码所有者知道谁审阅该文件。部署系统知道哪个提交已生效。问题跟踪器知道上周是否发生了同样的故障。
每个系统都很有用。问题是他们之间的差距。
当工程师在事件发生的前十五分钟在选项卡之间移动时,组织将支付两倍的费用。该错误仍然存在,最有能力推理它的人正在集中精力处理文书工作。
搜索不是上下文
搜索日志 错误 可以发现噪音。搜索状态代码的痕迹可以找到症状。按时间戳搜索提交可以找到候选者。
这些都与上下文不同。
上下文意味着事件简介已经回答了经验丰富的工程师首先会问的问题:
- 哪条客户路径失败了?
- 涉及哪个服务、端点、作业或队列?
- 故障是在部署后开始的吗?
- 跟踪中出现哪个代码路径?
- 谁拥有相关文件?
- 这个签名以前出现过吗?
- 最小的可行修复或回滚路径是什么?
该简报应该在值班工程师开始打字之前就已存在。
更好的首屏
事件中的第一个屏幕应该感觉像是一个准备好的案例文件,而不是一个空白终端。
它应该显示生产信号、可疑的代码路径、最近的更改集和所有者。它应该将事实与猜测分开。当证据薄弱时应该说。如果有足够的信心起草修复拉取请求,则应该使用附加到审查中的相关日志和跟踪来完成此操作。
这并不能取代随叫随到的判断。它保护它。
人类的注意力最好花在问“这是正确的解决方案吗?”上。比“哪个标签有线索?”
审核前自动化应该做什么
良好的事件自动化应该处理无聊的调查步骤:
- 集群重复警报和错误事件。
- 将最有用的跟踪和日志提取到一份摘要中。
- 将失败窗口与部署历史记录进行比较。
- 将堆栈帧和跨度映射到文件、函数和所有者。
- 仅当证据支持时才起草最小补丁。
- 解释评审者需要验证的假设。
输出仍然可以是正常的拉取请求。事实上,应该如此。 Pull 请求已经包含审查、CI、所有权、讨论和审计跟踪。
待命标准应该改变
现在是 2026 年。基线不应该是工程师在凌晨 4 点生产中断时手动编写 shell 命令。
基线应该是一个读取事件、收集周围证据、将其连接到代码并向所有者提供可审查的下一步的系统。
待命总是需要判断力。它不应该首先要求像搜索引擎一样运行。