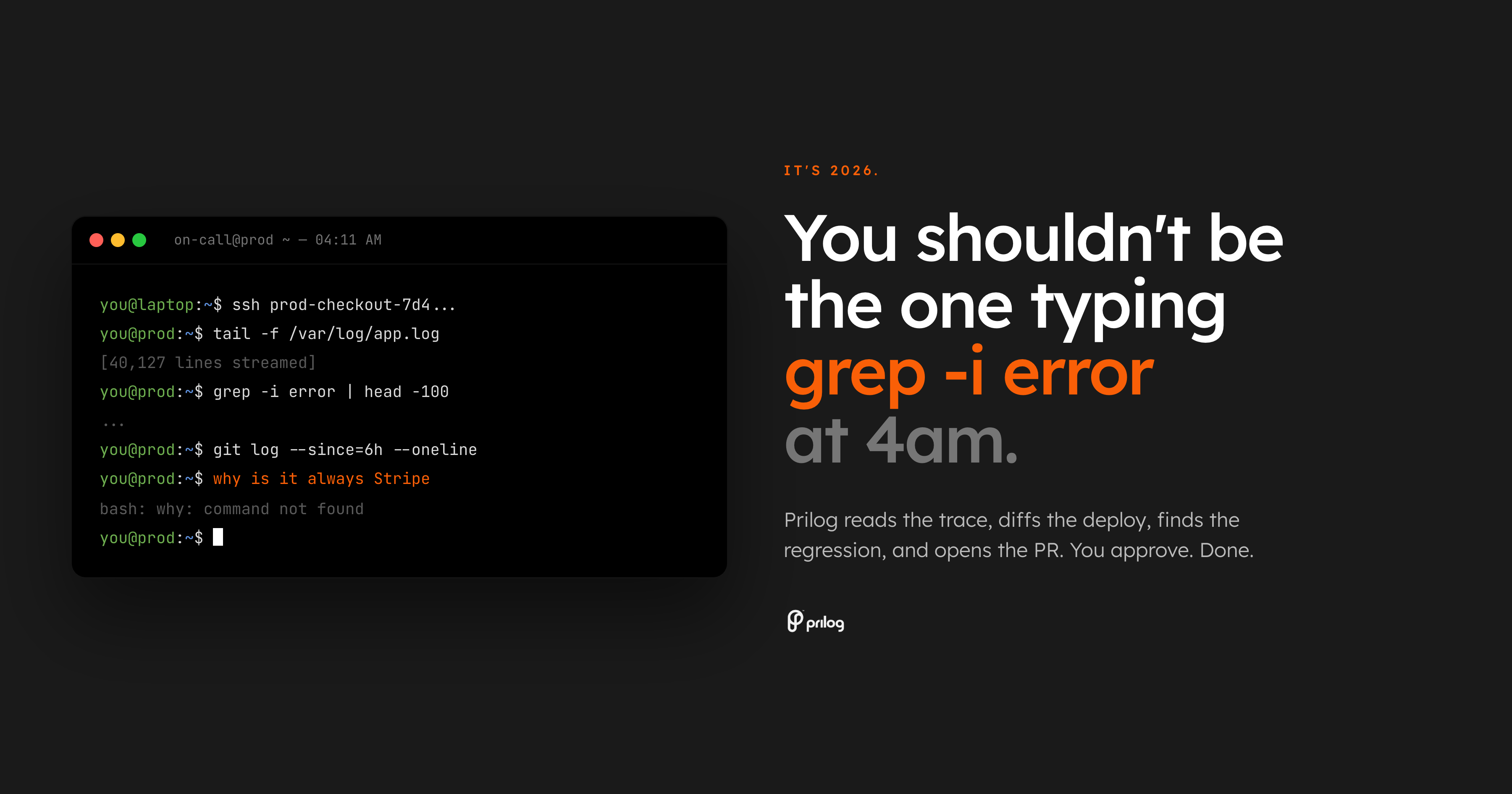
オンコールで一番最悪なのは、起こされないことです。それは目覚めさせられ、検索の問題を渡されます。
アラートは、チェックアウトエラーが増加していることを示しています。ダッシュボードで何かが間違っていることがわかります。その後、実際の作業が始まります。トレース ビューを開き、ログをスキャンし、最後のデプロイを比較し、所有者を探し、機能フラグの状態を確認し、古い Slack スレッドを検索し、バグが API、支払い、フロントエンド、またはインフラストラクチャに属するかどうかを判断します。
それはまだ診断ではありません。それが回収です。
インシデント対応における隠れた税金
ほとんどの実稼働デバッグ ワークフローでは、依然として人間がインデックス作成層であることを前提としています。ツールは信号を発しますが、エンジニアはそれらを接続する必要があります。
アラートによってサービスが認識される場合があります。トレースにより、障害が発生したスパンがわかる場合があります。ログ行に例外が含まれる場合があります。 Git は何が変わったかを知っています。 CODEOWNERS はファイルを誰がレビューするかを知っています。デプロイ システムは、どのコミットがライブになったかを認識します。問題トラッカーは、先週同じ障害が発生したかどうかを知っています。
それぞれの制度が便利です。問題はそれらの間のギャップです。
エンジニアがインシデントの最初の 15 分間をタブ間の移動に費やすと、組織は 2 倍の料金を支払うことになります。このバグは依然として生きており、それを最もよく推論できる人が事務作業に専念しています。
検索はコンテキストではありません
ログの検索 エラー ノイズを見つけることができます。ステータス コードのトレースを検索すると、症状を見つけることができます。タイムスタンプでコミットを検索すると、候補を見つけることができます。
そのどれもがコンテキストと同じではありません。
コンテキストとは、経験豊富なエンジニアが最初に尋ねるであろう質問に、インシデントの概要がすでに答えていることを意味します。
- どの顧客パスが失敗していますか?
- どのサービス、エンドポイント、ジョブ、またはキューが関係していますか?
- 障害はデプロイ後に始まりましたか?
- トレースにはどのコード パスが表示されますか?
- 関連ファイルの所有者は誰ですか?
- このサインは以前にも登場したことがありますか?
- 最も妥当な修正またはロールバック パスは何ですか?
この概要は、オンコール エンジニアが入力を開始する前に存在している必要があります。
より良い最初の画面
インシデントの最初の画面は、空の端末ではなく、準備された事件ファイルのように感じられる必要があります。
ここには、運用シグナル、疑わしいコード パス、最近の変更セット、および所有者が表示されます。事実と推測を区別する必要があります。証拠が弱い場合は言うべきです。修正プル リクエストを作成するのに十分な自信がある場合は、レビューに添付された関連ログとトレースを使用して修正プル リクエストを作成する必要があります。
これはオンコールの判断に代わるものではありません。それはそれを保護します。
人間の注意は、「これは正しい解決策ですか?」と自問することに費やしたほうがよいでしょう。 「どのタブにヒントがありましたか?」
レビューの前に自動化が行うべきこと
適切なインシデント自動化では、退屈な調査手順を処理する必要があります。
- 重複したアラートとエラー イベントをクラスター化します。
- 最も有用なトレースとログを 1 つの要約にまとめます。
- 失敗ウィンドウをデプロイ履歴と比較します。
- スタック フレームとスパンをファイル、関数、および所有者にマップします。
- 証拠がそれを裏付ける場合にのみ、最小限のパッチをドラフトしてください。
- レビュー担当者が検証する必要がある仮定を説明します。
出力は通常のプル リクエストである場合もあります。実際、そうあるべきです。プル リクエストには、レビュー、CI、所有権、ディスカッション、監査証跡がすでに含まれています。
オンコールの基準を変える必要がある
時は 2026 年です。運用が中断されている午前 4 時にエンジニアがシェル コマンドを手動で作成することがベースラインであってはなりません。
ベースラインは、インシデントを読み取り、周囲の証拠を収集し、コードに関連付けて、所有者にレビュー可能な次のステップを渡すシステムである必要があります。
オンコールでは常に判断が必要になります。最初に検索エンジンのように動作する必要はありません。