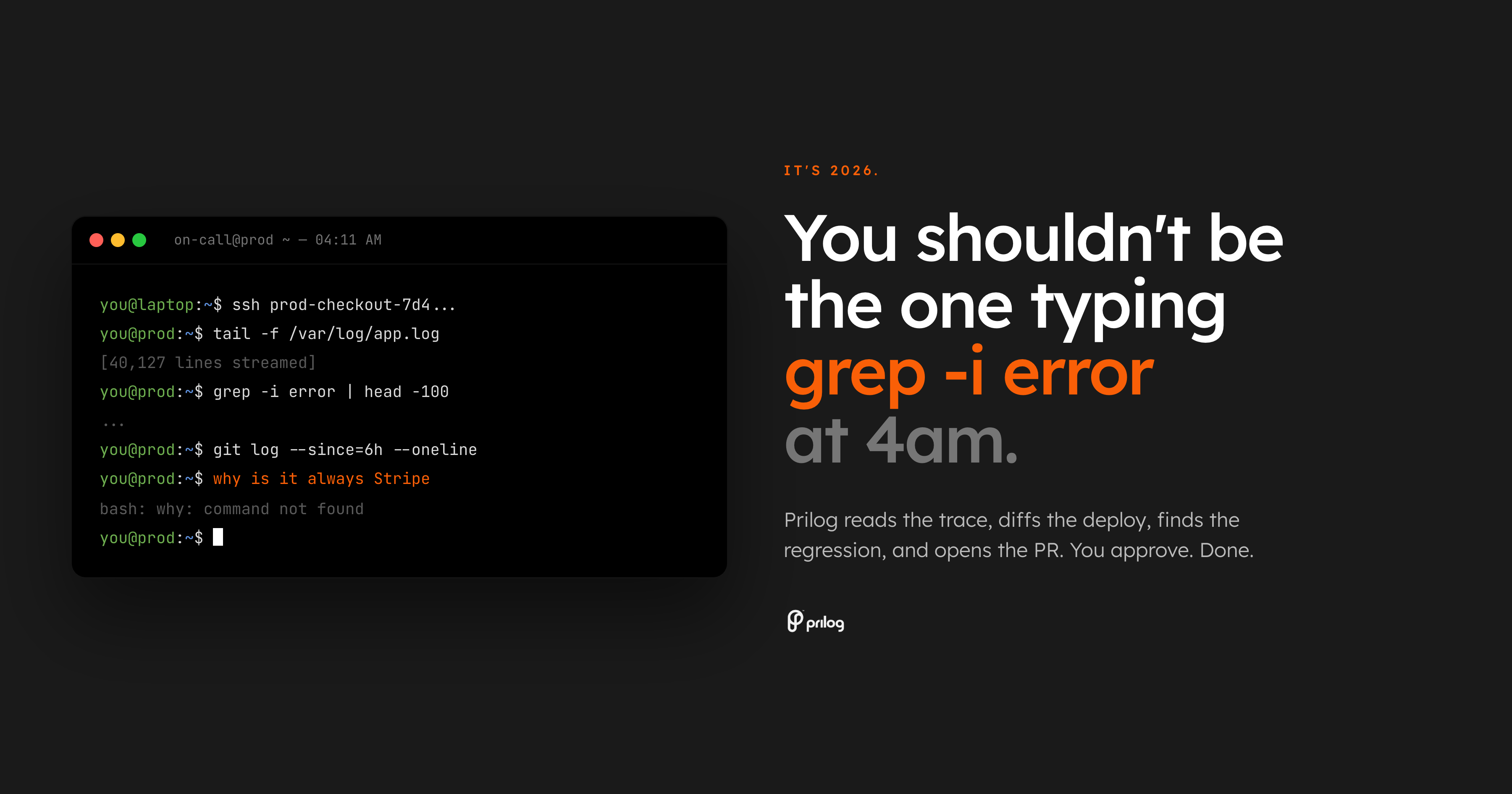
The worst part of on-call is not being woken up. It is being woken up and handed a search problem.
The alert says checkout errors are rising. The dashboard confirms something is wrong. Then the real work starts: open the trace view, scan logs, compare the last deploy, look for the owner, check the feature flag state, search old Slack threads, and decide whether the bug belongs to API, payments, frontend, or infrastructure.
That is not diagnosis yet. That is retrieval.
The hidden tax in incident response
Most production debugging workflows still assume the human is the indexing layer. Tools emit signals, but the engineer has to connect them.
An alert might know the service. A trace might know the failing span. A log line might include the exception. Git knows what changed. CODEOWNERS knows who reviews the file. The deploy system knows which commit went live. The issue tracker knows whether the same failure happened last week.
Each system is useful. The problem is the gap between them.
When an engineer spends the first fifteen minutes of an incident moving between tabs, the organization pays twice. The bug remains live, and the person best able to reason about it is burning attention on clerical work.
Search is not context
Searching logs for error can find noise. Searching traces for a status code can find symptoms. Searching commits by timestamp can find candidates.
None of that is the same as context.
Context means the incident brief already answers the questions an experienced engineer would ask first:
- What customer path is failing?
- Which service, endpoint, job, or queue is involved?
- Did the failure start after a deploy?
- Which code path appears in the trace?
- Who owns the relevant files?
- Has this signature appeared before?
- What is the smallest plausible fix or rollback path?
That brief should exist before the on-call engineer starts typing.
A better first screen
The first screen in an incident should feel like a prepared case file, not a blank terminal.
It should show the production signal, the suspected code path, the recent change set, and the owner. It should separate facts from guesses. It should say when evidence is weak. If there is enough confidence to draft a remediation pull request, it should do that with the relevant logs and traces attached to the review.
This does not replace on-call judgment. It protects it.
Human attention is better spent asking, "Is this the right fix?" than, "Which tab had the clue?"
What automation should do before review
Good incident automation should handle the boring investigation steps:
- Cluster duplicate alerts and error events.
- Pull the most useful traces and logs into one summary.
- Compare the failure window with deploy history.
- Map stack frames and spans to files, functions, and owners.
- Draft a minimal patch only when the evidence supports it.
- Explain the assumptions a reviewer needs to validate.
The output can still be a normal pull request. In fact, it should be. Pull requests already carry review, CI, ownership, discussion, and an audit trail.
The on-call standard should change
It is 2026. The baseline should not be an engineer manually composing shell commands at 4am while production is broken.
The baseline should be a system that reads the incident, gathers the surrounding evidence, connects it to code, and hands the owner a reviewable next step.
On-call will always require judgment. It should not require acting like a search engine first.